David A Notes YOUR OFFWORLD INVESTMENTS IN ARTIFICIAL DUMBNESS PAID $? IN DIVIDENDS
Conway and Coase on Collaboration in Software

Building software is a team sport, but who’s on your team? The answer may surprise you! Conway & Coase Conway’s Law states that the structure of a large software project will inevitably come to resemble the organizational structure of the teams who build it. Colloquially, you are destined to “ship your org chart.” A critical insight here i... Read more 17 Mar 2024 - 3 minute read
Engineering as Shadow Price Discovery

Engineering: solving problems under constraints Many engineering problems have the general form of trying to achieve some desired capabilities at minimum cost, or alternatively trying to design the best performing system within a certain price point. For purposes of a concrete example, say we are designing one of those rolling delivery robots l... Read more 30 Oct 2022 - 8 minute read
Software problems

What do you do with a problem like software? Everyone in technology loves solving problems, you can just read their cover letters and LinkedIn bios where they say so. But what are “problems” in the context of software, exactly? What follows below is a crude and idiosyncratic categorization of some different problem flavors one might encounter ... Read more 06 Sep 2022 - 9 minute read
Encoder: Elements of Clojure by Zachary Tellman

Encoder: experimenting with posting summaries or highlights of my (often quite) rough notes on books or papers I’ve read. Elements of Clojure by Zachary Tellman Names are not the only means of creating indirection, but they are the most common. The act of writing software is the act of naming, repeated over and over again.— Elements ... Read more 20 Aug 2022 - 3 minute read
Career links: teams and business
Disclaimer: Not advice, consult a professional! Following on a previously posted collection of links, here is another collection of resources focused on more organization-oriented topics. These are not exhaustive, and indeed some of these resources likely contradict each other outright. As in previous post, the reader is encouraged to take ... Read more 09 Sep 2021 - 2 minute read
Career links: ladder-climbing vs bet-placing

Disclaimer: Not advice, consult a professional! Software engineers (like anyone) often want a structured framework for thinking about career progression and growth. Many companies provide this in the form of a career ladder, and there are a wide variety of resources for learning more about developing skills and achieving milestones correspo... Read more 08 Sep 2021 - 7 minute read
Models and iteration speed in coding

“The best material model of a cat is another, or preferably the same, cat.” -Arturo Rosenblueth and Norbert Wiener, The Role of Models in Science What do programmers do when they are programming? One interpretation is that they are high-throughput empiricists, iteratively developing and testing many small hypotheses about what various piece... Read more 21 Jan 2021 - 6 minute read
Graphs, combinatorial optimization, and product development
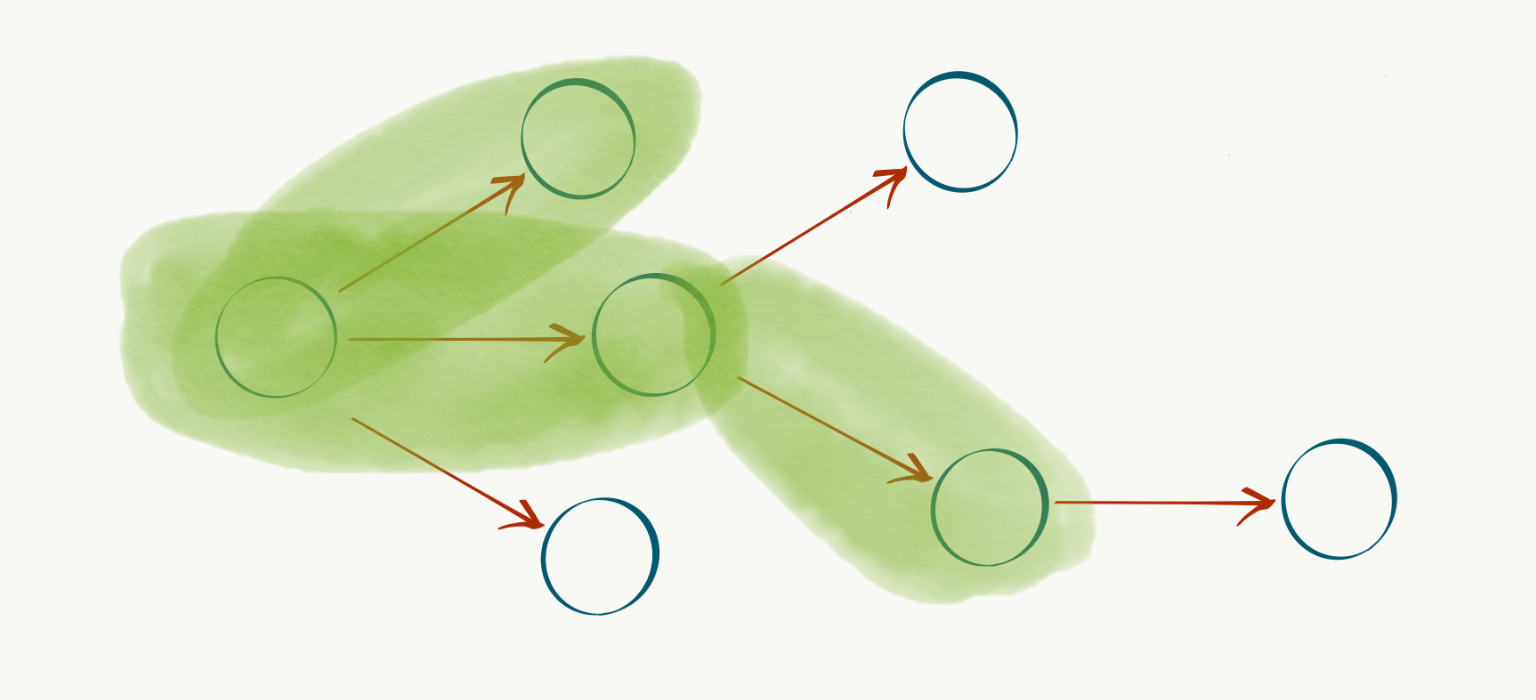
Introduction Software product development can be thought of as spending scarce time, effort, and attention in order to (hopefully) deliver customer value. The actual details of how this happens in practice are rarely as simple as “go build XYZ”, instead messy reality consists of an interconnected web of target users and use cases, deliverables ... Read more 24 Jul 2020 - 9 minute read
Self-explainer: privacy-preserving contact tracing
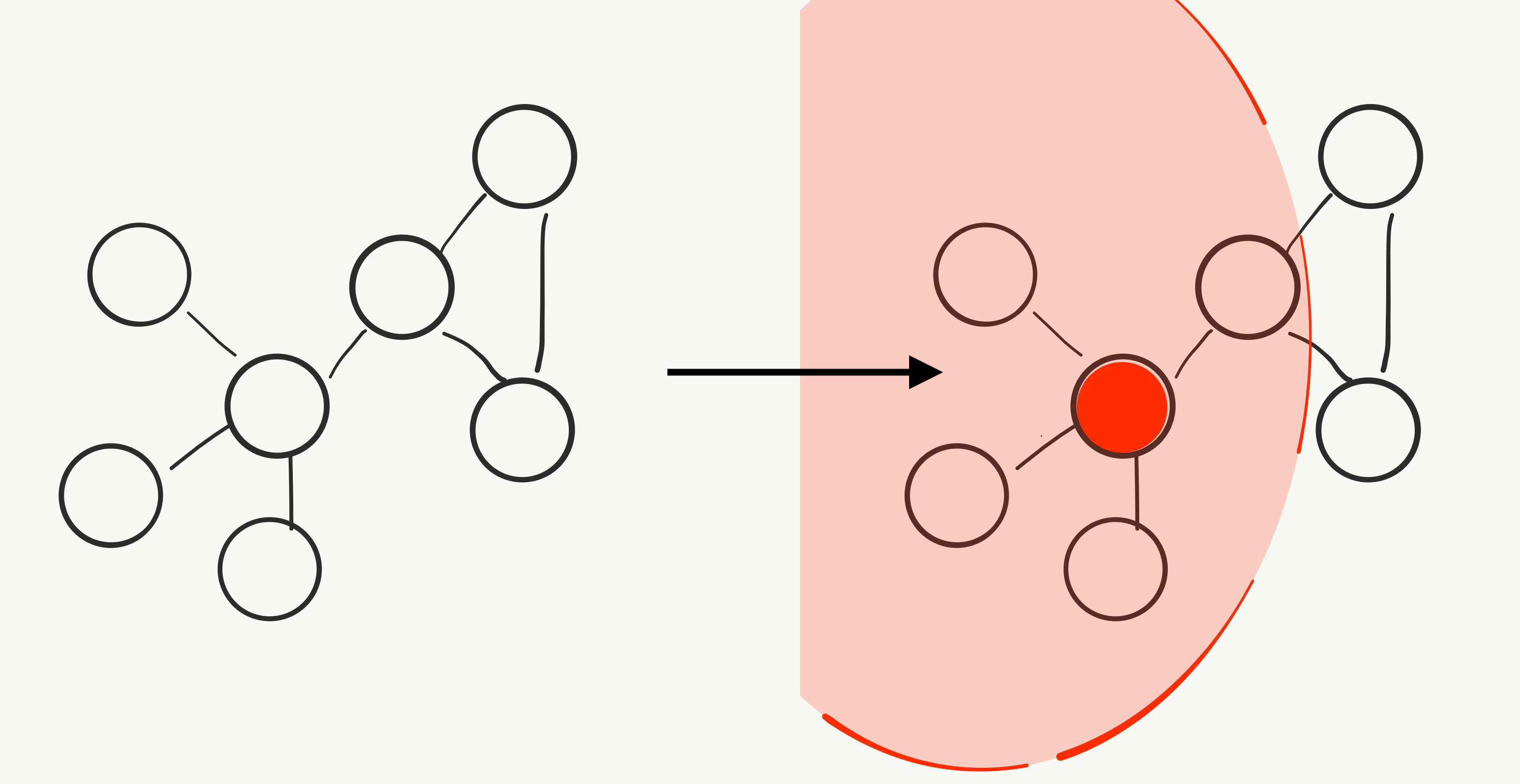
Self-explainer: experimenting with taking my usual rough notes on various topics of interest and posting only very slightly nicer versions of them publicly. Context and problem Way back in the first few weeks of the Bay Area pandemic shelter-in-place orders, I happened upon an interesting tweet from Carmela Troncoso, a security professor a... Read more 26 Apr 2020 - 5 minute read
Techniques of interest
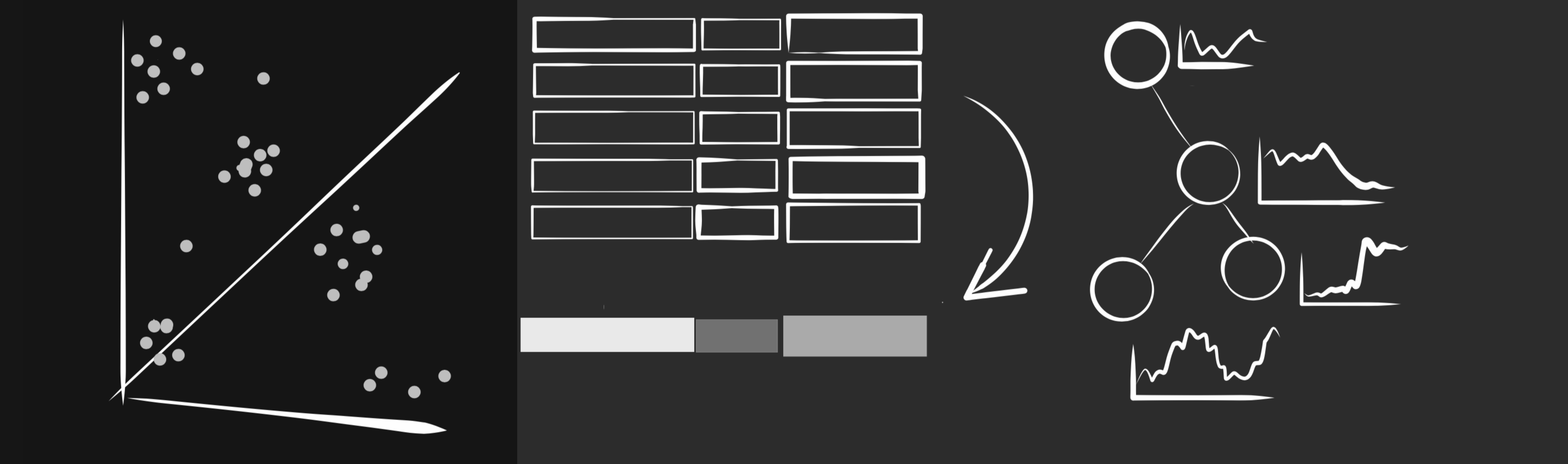
Note: cross-posted from my website, where I recently attempted to jot down some brief descriptions of the problem domain I’m currently focused on as well as some tools and techniques I am particularly interested in. Machine learning One might expect software system behavior and its associated telemetry to be perfectly well-orde... Read more 31 Jan 2020 - 3 minute read